Chapter 6 Descriptives
Descriptive statistics describe basic features of the data in simple summaries. Examples include reporting measures of central tendency such as the mean, median, and mode. These are values that represent the most typical or most central point of a data distribution. Another class of descriptives are measures of variability or variation such as variance, standard deviation, ranges or interquartile ranges. These measures describe the spread of data. As well as being useful summaries in their own right, descriptive statistics are also used in data visualization to summarize distributions. There are several functions in R and other packages that help to get descriptive statistics from data. Before we go into detail about how to use R to get descriptives, we’ll describe these measures of central tendency and variation in a bit more detail.
6.1 Sample vs Population
The first thing we would like to discuss is the difference between samples and populations. We can calculate descriptive measures such as means and standard deviations for both samples and populations, but we use different notation to describe these. A population is all subjects that we could possibly collect data from. For example, if we were interested in the IQ scores of eighth graders in Texas, then our population of interest is all eighth graders in Texas. If we wished to study maze learning in juvenile rats, then our population of interest would be all juvenile rats. If we were studying leaf growth in sunflowers, then our population of interest is all sunflowers. If we were able to measure the size of leaves on all sunflowers in existence, or measure the maze learning of all juvenile rats in the world, or the IQ of all eighth graders in Texas, then we would have data for the whole population. We would then be able to say something about the mean or median or some other descriptive about the population. Clearly, it is not always possible to measure every subject in a population. Of our three examples, it may just about be possible to measure the IQ of all Texas eighth graders although it would be a lot of work. It seems unlikely to be possible to measure the leaf growth of all sunflowers or the maze learning of all juvenile rats. Instead, what we typically do is to collect data on a subset of subjects. We call this subset a sample. For instance, if we picked 10 sunflowers then we would collect data on just those sunflowers. We may be able to calculate the average leaf size of these 10 sunflowers and use that to estimate what the true leaf size is of all sunflowers. We call the descriptive measures of samples estimates or statistics, whereas the descriptive measures of populations are called parameters.
Let’s now discuss different descriptive measures in turn.
6.2 Sample and Population Size
This isn’t strictly a descriptive measure - but it is worth pointing out that the notation for the size of your data is different depending upon whether you are talking about a sample of a population. If you are taking about a sample, then we use the lower case \(n\) to refer to the sample size. So, if you see \(n=10\) this means that the sample size is 10. e.g. you picked 10 sunflowers to collect data on. If you see the upper case \(N\) this refers to the population size. So if you see that the population size is \(N=1200000\) this refers to a population size of 1.2 million.
6.3 Central Tendency
The first class of descriptives we will explore are measures of central tendency. These can be thought of as values that describe what is the most common, most typical or most average value in a distribution. Also, here we are using the term distribution to refer to a group of numbers or our data.
We’ll use the following dataset as an example. Let’s imagine that this is a sample of data:
x <- c(1, 14, 12, 5, 3, 6, 11, 15, 9, 5, 4, 2, 7, 5, 3, 8, 11)
x## [1] 1 14 12 5 3 6 11 15 9 5 4 2 7 5 3 8 11We can calculate the sample size using length():
length(x)## [1] 17We can see that the sample size is \(n=17\).
6.3.1 Mode
The mode or modal value of a distribution is the most frequent or most common value in a distribution. The number that appears the most times in our sample of data above is 5. The mode is therefore 5. In our example, it’s possible to manually check all the values, but a quicker way to summarize the frequency count of each value in a vector in R is to use table() like this:
table(x)## x
## 1 2 3 4 5 6 7 8 9 11 12 14 15
## 1 1 2 1 3 1 1 1 1 2 1 1 1We can see that there are 3 instances of the number 5 making it the mode. There are two instances of 11 and 3, and every other number in the distribution has only 1 instance.
Is 5 really the ‘middle’ of this distribution though? The mode has some serious deficiencies as a measure of central tendency in that although it picks up on the most frequent value, that value isn’t necessarily the most central measure.
6.3.2 Median
The median value is the middle value of the distribution. It represents the value at which 50% of the data lies above the median, and 50% lies below the data.
One way to look at this is to visualize our distribution as a dot plot:
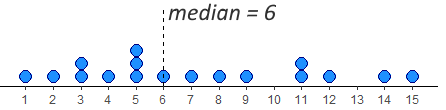
We have 17 datapoints, which is an odd number. In this case, we want the number/dot at which half the remaining datapoints (8) are below the median, and half (the other 8) are above the median. You can see in the image, that the median value is therefore 6. This leaves 8 dots below it and 8 dots above it.
To do this by hand, we would first order the data, and then work from the outside to the inside of the distribution, crossing off one from each end at a time. The image below shows how we’re doing that using different colors to show the crossing out:
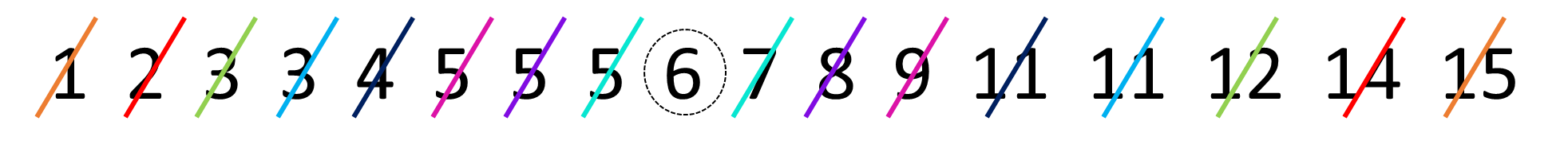
In R, we have a quick shortcut for calculating the median, and it’s to use the function called median():
median(x)## [1] 6If we have an even number of values in our distribution, then we take the average of the middle two values. For example, look at the image below. It has 12 numbers in the distribution, so we take the average of the 6th and 7th number:
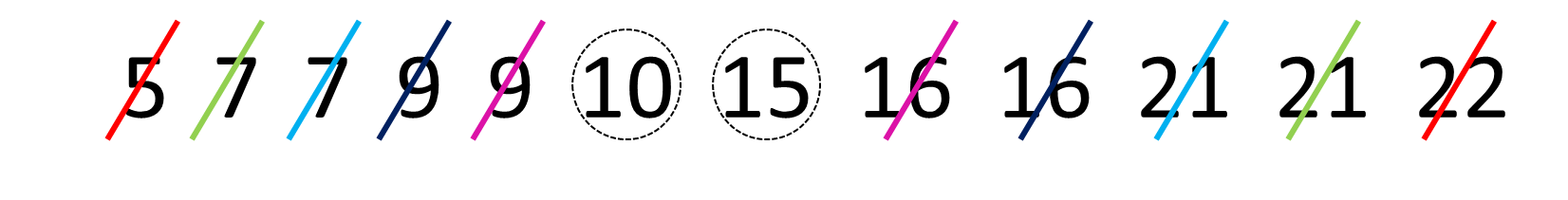
Once we’ve crossed out each number going from outside to in, we’re left with the 6th and 7th numbers being 10 and 15. The average of these numbers is 12.5, so the median is 12.5. We can see that with median():
y <- c(5,7,7,9,9,10,15,16,16,21,21,22)
median(y)## [1] 12.56.3.3 Mean
The mean, or arithmetic mean is the measure that most people think about when they think of the average value in a dataset or distribution. There are actually various different ways of calculating means, so the one that we will focus on is called the arithmetic mean. This is calculated by adding up all the numbers in a distribution and then dividing by the number of datapoints. You can write this as a formula. For a sample, it looks like this:
\(\overline{x} = \frac{\Sigma{x}}{n}\)
And for a population it looks like this:
\(\mu = \frac{\Sigma{x}}{N}\)
Notice that we use \(\overline{x}\) to denote the mean of a sample, and \(\mu\) to denote the mean of a population. Despite these notation differences, the formula is essentially exactly the same.
Let’s calculate the arithmetic mean of our distribution x:
sum_of_x <- 1 + 14 + 12 + 5 + 3 + 6 + 11 + 15 + 9 + 5 + 4 + 2 + 7 + 5 + 3 + 8 + 11
sum_of_x## [1] 121So, here \(\Sigma{x}=121\). That makes the mean:
sum_of_x / 17## [1] 7.117647This makes the mean \(\overline{x}=7.12\). The shortcut way of doing this in R, is to use the function mean():
mean(x)## [1] 7.117647We’ll talk more about the pros and cons of the mean and median in future chapters.
6.4 Variation
As well as describing the central tendency of data distributions, the other key way in which we should describe a distribution is to summarize the variation in data. This family of measures look at how much spread there is in the data. Another way of thinking about this is that these measure give us a sense of how clumped or how spread out the data are.
6.4.1 Range
The simplest measure of spread is the range. This simply is the difference between the minimum and maximum value in a dataset. Looking at our distribution x, the minimum value is 1, and the maximum value is 15 - therefore the range is \(15-1 = 14\).
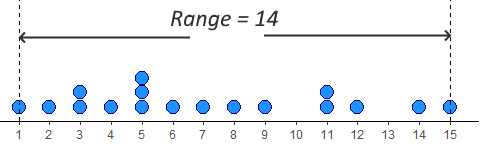
The problem with range as a measure can be illustrated by just adjusting our data distribution slightly. Say, instead of having a datapoint at 15, we had a value at 25. Now the range is 24 instead of 14. This suggests that the data is much more spread out, but in reality it is just one datapoint that is forcing the range to be much higher - the rest of the data is no more clumped or spread out. This is the major drawback of the range - it can be easily influenced by outliers - as illustrated below.
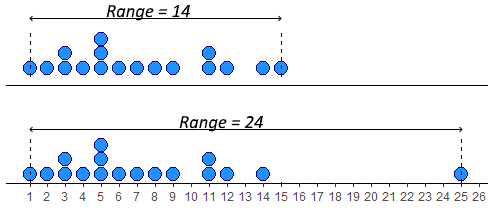
In R, we can calculate the minimum, maximum and range of a distribution using the functions min(), max() and range(). Although range() just gives us the minimum and maximum values, we have to do the rest:
min(x)## [1] 1max(x)## [1] 15range(x)## [1] 1 156.4.2 Interquartile Range
The interquartile range or IQR is another measure of spread. It is roughly equivalent to the range of the middle 50% of the data. One way to think about this is to consider how the median splits the data into a bottom half and a top half. Then, calculate the median of the lower half of the data and the median of the upper half of the data. These values can be considered to be the lower quartile and upper quartile respectively. The interquartile range is the difference between these values. A visualization of this is below:
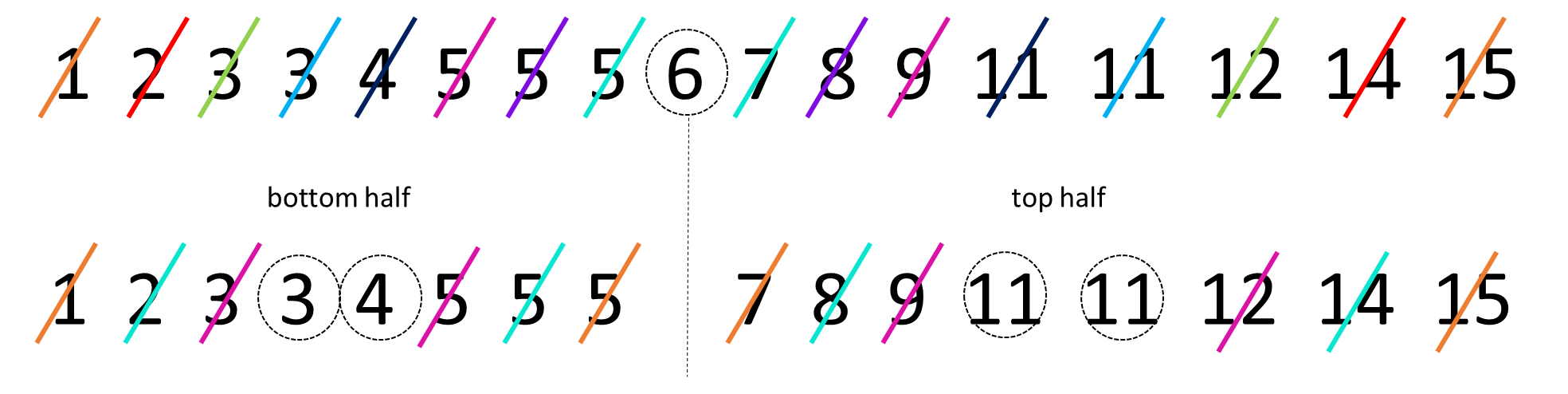
The median of the bottom half of our data is 3.5 (the average of 3 and 4). The median of the top half is 11 (the average of 11 and 11). This makes the IQR equal to \(11-3.5 = 7.5\).
If we start with an even number of numbers in our distribution, then we include each of the middle numbers in their respective lower and upper halves. The image below represents this:

With this distribution, we calculated the median to be 12.5 as the numbers 10 and 15th were the middle two values. Because of this, we include 10 in the bottom half and 15 in the top half. When we work out to in on each of these halves, we find that the median of the bottom half is 8 (the average of 7 and 9) and the median of the upper half is 18.5 (the average of 16 and 21). Therefore, the lower quartile is 8 and the upper quartile is 18.5, making the IQR equal to \(18.5-8=10.5\).
The above explanation of how to calculate the IQR is actually just one way of trying to estimate the “middle 50%” of the data. With this way of doing it, the lower quartile represents the 25% percentile of the data (25% of values being lower than it and 75% of values being higher). The upper quartile represents the 75% percentile of the data (75% of values being lower than it and 25% being higher).
Unfortunately, there are several ways of calculating the lower and upper quartiles and estimating where these 25% and 75% percentiles are. When we calculate them in R, the default method it uses is actually different to our ‘by hand’ method. To calculate quartiles, we use the function quantile() (note - not quartile!) but we have to put a second argument to say if we want the lower quartile or upper quartile.
quantile(x, 0.25) #0.25 means lower quartile## 25%
## 4quantile(x, 0.75) #0.75 means upper quartile## 75%
## 11You can see these values are slightly different to our ‘by hand’ method. The upper quartile of x agrees with our method being 11. By hand we got the lower quartile to be 3.5, but R gives it as 4. This would make the IQR equal to \(11-4 =7\). The quick way of getting that in R is to use IQR():
IQR(x)## [1] 7We recommend using the R functions to calculate quartiles and interquartile ranges - it is a slightly stronger method than our by-hand method. You can actually do the by-hand method in R by adding type=6 to the functions. There are actually nine different ways of calculating these in R - which is ridiculous!
quantile(x, 0.25, type = 6)## 25%
## 3.5quantile(x, 0.75, type = 6)## 75%
## 11IQR(x, type = 6)## [1] 7.56.4.3 Average Deviation
An alternative way of looking at spread is to ask how far from the center of the data distribution (i.e. the mean) is each datapoint on average. Distributions that are highly clumped will have most datapoints very close to the distribution’s mean. Distributions that are spread out will have several datapoints that are far away from the mean.
Look at the two distributions below. Both of them have means of 10. The top distribution (A) however is much more clumped than the bottom distribution (B) which is more spread out.
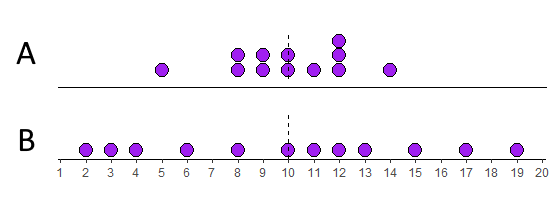
Let’s look at these in more detail. We’ll start with distribution A. We can calculate the difference of each datapoint from the mean (10) like this:
A <- c(5,8,8,9,9,10,10,11,12,12,12,14)
A - mean(A)## [1] -5 -2 -2 -1 -1 0 0 1 2 2 2 4If we add up all of those differences from the mean, then they will equal 0. We can show this like this:
sum(A - mean(A))## [1] 0A way to count up all the differences from the mean and to make sure that they count is to make each number positive regardless of its sign. We can do this using abs() in R:
abs(A - mean(A))## [1] 5 2 2 1 1 0 0 1 2 2 2 4When we sum all of these values up, we get the total of all the differences from the mean of each datapoint:
sum(abs(A - mean(A)))## [1] 22We see that this total is 22. In formula notation, we find that \(\Sigma|(x - \overline{\mu})|\). Here \(x\) represents each datapoint. \(\overline{\mu}\) represents the population mean. \(| |\) represents ‘take the absolute values of’, and \(\Sigma\) means “sum up”.
To get the “average deviation” we simply divide our sum of difference scores by the number of datapoints, which is 12 in this case. The formula for average deviation is:
\(AD = \frac{\Sigma|(x - \overline{\mu})|}{N}\)
22/12## [1] 1.833333Our average deviation is therefore 1.83. This can be interpreted as each datapoint being on average 1.83 units away from the mean of 10.
Another way to have got the \(N\) would have been to use length() which counts the number of datapoints:
sum(abs(A - mean(A))) / length(A)## [1] 1.833333We could do the same for distribution B. Calculate the sum of all the difference scores, and then divide by the \(N\):
B <- c(2,3,4,6,8,10,11,12,13,15,17,19)
#difference scores
B - mean(B)## [1] -8 -7 -6 -4 -2 0 1 2 3 5 7 9# absolute difference scores
abs(B - mean(B))## [1] 8 7 6 4 2 0 1 2 3 5 7 9# sum of absolute difference scores
sum(abs(B - mean(B)))## [1] 54# average deviation
sum(abs(B - mean(B))) / length(B)## [1] 4.5Here, the total sum of differences from the mean is 54. The average deviation is 4.5. This value being higher than 1.83, shows that distribution B is more spread out than distribution A, which makes sense just looking at the dotplots of the data.
6.4.4 Standard Deviation
An alternative, and much more common method of calculating the ‘deviation’ from the mean of the average datapoint is the standard deviation. This is very similar to the absolute deviation, but the method of making the difference scores positive is different. In average deviation, we just ignore the sign of the difference scores and we make everything positive (this is called taking the absolute value). In standard deviation the method used to make these difference scores positive is to square them.
Let’s look at how this one works for our two distributions. We’ll start with distribution A again.
First step, is again to get the difference scores, by taking each datapoint away from the mean of the distribution:
A - mean(A)## [1] -5 -2 -2 -1 -1 0 0 1 2 2 2 4Next, we square these difference scores to get positive values:
(A - mean(A))^2## [1] 25 4 4 1 1 0 0 1 4 4 4 16Notice that the datapoints that are furthest from the mean get proportionally larger than values that are close to the mean. Squaring has this effect.
We need to sum these “squared differences” to get a measure of how much deviation there is in total - this figure can also be called the Sum of Squares or Sum of Squared Differences:
sum((A - mean(A))^2)## [1] 64The total of the squared differences is 64. The notation for this is:
\(\Sigma(x-\mu)^2\)
To get a sense of the average squared difference, we then divide the total of the squared differences by our \(N\):
sum((A - mean(A))^2) / 12## [1] 5.333333The average squared difference is 5.33. The notation for this is \(\frac{\Sigma(x-\mu)^2}{N}\).
This is a useful measure of deviation, but unfortunately it is still in the units of “squared differences”. To get it back to the original units of the distribution we just square root it and we call this the “standard deviation”:
sqrt(5.333333) ## [1] 2.309401The standard deviation \(\sigma=2.309\). The notation for this is:
\(\sigma = \sqrt{\frac{\Sigma(x-\mu)^2}{N}}\)
We are using \(\sigma\) to represent the population standard deviation.
We can do the same thing for our population B. Let’s calculate the difference scores, then square them, then add them up, then divide by \(N\), and finally square root:
# difference scores
B - mean(B)## [1] -8 -7 -6 -4 -2 0 1 2 3 5 7 9# squared difference scores
(B - mean(B))^2## [1] 64 49 36 16 4 0 1 4 9 25 49 81# Sum of squared differences
sum((B - mean(B))^2)## [1] 338# Average squared difference
sum((B - mean(B))^2) / 12## [1] 28.16667# Standard Deviation
sqrt(sum((B - mean(B))^2) / 12)## [1] 5.307228The population standard deviation \(\sigma\) for population B is 5.31. Again, as this value is higher than 2.31 this suggests that population B is more spread out than population A, because its datapoints are on average further from the mean.
6.4.5 Variance
Variance is related to standard deviation. In fact, it is just standard deviation squared. It can be calculated by the formula:
\(\sigma^2 = \sigma^2\)
which is a bit ridiculous. Variance is denoted by \(\sigma^2\) and is calculated by squaring the standard deviation \(\sigma\).
It’s actually the value you get before you do the square root step when calculating standard deviation. Therefore, we can actually say:
\(\sigma^2 = \frac{\Sigma(x-\mu)^2}{N}\)
6.4.6 Average versus Standard Deviation
So why do we have two methods for calculating the deviation from the mean. We have the “average deviation” and the “standard deviation”. One thing you should notice is that the standard deviation is larger than the average deviation. Distribution A had an average deviation of 4.5 and a standard deviation of 5.3. Distribution B had an average deviation of 1.83 and a standard deviation of 2.3. The reason for this is that squaring difference scores leads to larger values than just taking absolute values. So why do we do the squaring thing? The main reason is that it emphasizes datapoints that are further away from the mean, and this can be an important aspect of spread that we need to take account for. Because of that, it is favored to use the ‘standard deviation’ above the ‘average deviation’.
6.4.7 Sample Standard Deviation
Something that is often confusing in introductory statistics is that there are two different formulas for calculating the standard deviation. The one we have already introduced above is called the population standard deviation and its formula is:
\(\sigma = \sqrt{\frac{\Sigma(x-\mu)^2}{N}}\)
But, we use a different formula when we are calculating the standard deviation for a sample. This is called the sample standard deviation:
\(s = \sqrt{\frac{\Sigma(x-\mu)^2}{n-1}}\)
Notice two things. First, we use the notation \(s\) to indicate a sample standard deviation. Second, instead of dividing by \(N\) in the formula, we divide by \(n-1\).
So, for our example data distribution of A, this is how we would calculate \(s\):
First, we get the difference scores, by subtracting the mean of the distribution from each score:
#difference scores
A - mean(A)## [1] -5 -2 -2 -1 -1 0 0 1 2 2 2 4Second, we square these difference scores to make them positive and to emphasize larger difference scores:
#square the difference scores
(A - mean(A))^2## [1] 25 4 4 1 1 0 0 1 4 4 4 16Third, we sum up all the squared difference scores:
#sum the squared difference scores
sum((A - mean(A))^2)## [1] 64Fourth, we divide this sum by \(n-1\), which technically gives us the variance:
#divide by n-1 to get the variance
# the 'n' is 12 here
(sum((A - mean(A))^2))/(12-1)## [1] 5.818182Finally, we square root this value to get the sample standard deviation - a measure of the typical deviation of each datapoint from the mean:
#square root to get the SD
sqrt((sum((A - mean(A))^2))/(12-1))## [1] 2.412091Here we have manually calculated the sample standard deviation \(s=2.412\). Earlier in this chapter we calculated the population standard deviation of this same distribution to be \(\sigma=2.309\). Notice that the sample standard deviation \(s\) is larger than the population standard deviation \(\sigma\). This is because \(n-1\) will always be smaller than \(N\), inflating the final result.
So far, we haven’t shown you the shortcut for calculating the standard deviation in R. It’s actually just the function sd():
sd(A)## [1] 2.412091Hopefully you notice that the output of sd() is the sample standard deviation and not the population standard deviation.
There is actually no built in function for calculating the population standard deviation \(\sigma\) in R. The below code is a custom function to calculate it that we made. It’s called pop.sd().
# this is a custom function to calculate
# the population standard deviation
pop.sd <- function(s) {
sqrt(sum((s - mean(s))^2)/length(s))
} When we look at the population standard deviation of A we can see that it matches what we worked out by hand earlier:
pop.sd(A) ## [1] 2.309401Let’s look at distribution B for its sample and population standard deviations:
sd(B)## [1] 5.543219pop.sd(B)## [1] 5.307228Again you can see that \(s=5.543\) is greater than \(\sigma=5.307\). Both these values are higher than the standard deviations for distribution A, indicating that distribution B is more spread out and less clumped than distribution A.
6.4.8 Sample versus Population Standard Deviation
So why are there two formulas, and why do we divide by \(n-1\) in the sample standard deviation? The short answer is that whenever we determine the standard deviation for a sample, our goal is technically not to ‘calculate’ the standard deviation just for that sample. The bigger goal is that we are trying to estimate the population standard deviation \(\sigma\). However, when we use the population SD formula on samples, we consistently underestimate the real population standard deviation. Why is this? Basically it’s for two reasons. First, within any one sample we typically have much less variation than we do in our population, so we tend to underestimate the true variation. Secondly, when we have our sample we use our sample mean \(\overline{x}\) as an estimate of the population mean \(\mu\). Because \(\overline{x}\) will be usually slightly different from \(\mu\) we will be usually underestimating the true deviation from the mean in the population.
The bottom line is this: using the population SD formula for a sample generally gives an underestimate of the true population standard deviation \(\sigma\). The solution is to use a fudge-factor of dividing by \(n-1\) which bumps up the standard deviation. This is what we do in the sample standard deviation formula.
In the sections below, we are going to visually demonstrate this. Hopefully this helps to show you that dividing by \(n-1\) works. Don’t worry too much about any code here, the aim isn’t for you to learn how to run simulations such as these, but we want you to be able to visually see what’s going on.
6.4.8.1 Comparing population and sample means
Before we get to why we need a separate formula for the sample standard deviation, let’s show you why we don’t need a separate formula for the sample mean compared to the population mean. Both of these formulas are essentially the same:
Sample mean: \(\Large\overline{x} = \frac{\Sigma{x}}{n}\)
Population mean:
\(\Large \mu = \frac{\Sigma{x}}{N}\)
Let’s assume the following data distribution is our population, we’ll call it pop. The following code creates a population of 10000 numbers drawn from a random normal distribution (see section 7.0.3) with a population mean of 8 and population standard deviation of 2. Because we’re randomly drawing numbers to make our population, the final population won’t have a mean and standard deviation that are precisely 8 and 2, but we can calculate what they turn out to be:
set.seed(1) # just so we all get the same results
pop <- rnorm(10000, mean = 8, sd = 2) #100 random numbers with mean of 8, popSD of 2.We now have our population of size \(N=10000\). We can precisely calculate the population mean \(\mu\) and population standard deviation \(\sigma\) of our 10000 numbers using mean() and pop.sd():
mean(pop) ## [1] 7.986926pop.sd(pop) ## [1] 2.024612So our population has a mean \(\mu=7.99\) and population standard deviation \(\sigma=2.02\).
Let’s now start taking samples. We’ll just choose samples of size \(n=10\). We can get samples using sample() in R. Let’s look at the sample mean of each sample:
#first sample
samp1 <- sample(pop, size = 10, replace = T)
samp1## [1] 3.722781 8.785220 6.045566 11.705993 7.297500 7.399121 11.976971
## [8] 8.401657 6.306361 7.152555mean(samp1)## [1] 7.879373Here our sample mean \(\overline{x}=8.62\) which is close-ish, but a fair bit above \(\mu=7.99\).
Let’s do it again:
#second sample
samp2 <- sample(pop, size = 10, replace = T)
samp2## [1] 6.142884 7.614448 9.575279 9.072075 4.108463 10.599279 8.224608
## [8] 6.735289 7.004465 7.791237mean(samp2)## [1] 7.686803Again our value of \(\overline{x}=8.10\) is above \(\mu=7.99\), but this time much closer.
Let’s do a third sample:
#third sample
samp3 <- sample(pop, size = 10, replace = T)
samp3## [1] 8.352818 12.802444 10.304643 6.061141 8.633719 8.028558 7.350359
## [8] 5.904344 6.875784 11.512439mean(samp3)## [1] 8.582625This time our value of \(\overline{x}=7.86\) is a bit below \(\mu=7.99\).
What if we did this thousands and thousands of times? Would our sample mean be more often lower or higher than the population mean \(\mu=7.99\)?
This is what the code below is doing - it’s effectively grabbing a sample of size 10 and then calculating the sample mean, but it’s doing this 20,000 times. It’s storing all the sample means in an object called results.means.
Note: you don’t need to know how this code works! though do reach out if you are interested.
results.means<- vector('list',20000)
for(i in 1:20000){
samp <- sample(pop, size = 10, replace = T)
results.means[[i]] <- mean(samp)
}Let’s look at 10 of these sample means we just collected:
unlist(results.means)[1:10]## [1] 7.457507 7.804544 8.099342 7.886644 7.642569 8.228794 8.581173 7.417380
## [9] 7.098994 7.458659Some are above and some are below \(\mu=7.99\).
Let’s calculate the mean of all the 20,000 sample means:
mean(unlist(results.means))## [1] 7.990952It turns out that the average sample mean that we collect using the formula \(\Large \overline{x} = \frac{\Sigma{x}}{n}\) is 7.99 which is the same as the population mean \(\mu\). What this means is that this formula is perfectly fine to use to estimate the population mean. It is what we call an unbiased estimator. Over the long run, it gives us a very good estimate of the population mean \(\mu\). Here is a histogram of our sample means from our 20,000 samples:
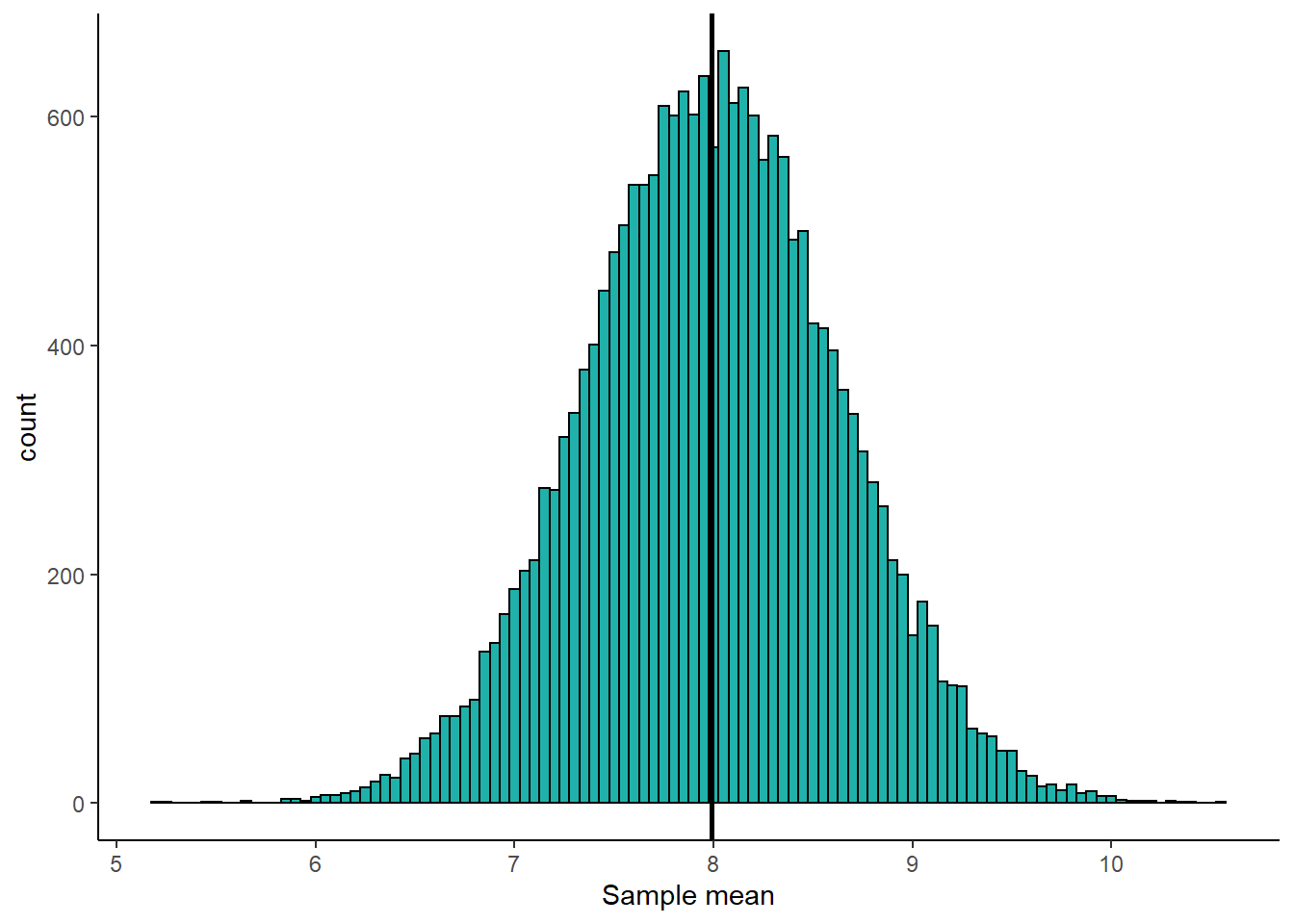
The vertical solid black line represents \(\mu=7.99\). This histogram is centered on this value, showing that our sample mean formula is unbiased in estimating the population mean - overall, it isn’t under- or over-estimating the population mean.
As a side note - what we just did in the exercise above was to calculate a sampling distribution of sample means - something we’ll discuss much more in section 7.2.
6.4.8.2 Sample standard deviation as an unbiased estimator
Let’s do something similar with our two formulas for calculating standard deviation. We’ll take samples of size \(n=10\) and use the sample standard deviation \(s\) and the population standard deviation \(\sigma\) formulas to estimate the true \(\sigma=2.02\).
#first sample
sd(samp1)## [1] 2.510835pop.sd(samp1)## [1] 2.381987With the first sample, both estimates are lower than \(\sigma=2.02\), although the sample standard deviation is a bit closer to \(\sigma=2.02\).
#second sample
sd(samp2)## [1] 1.850897pop.sd(samp2)## [1] 1.755915With the second sample of 10, both estimates are even lower than \(\sigma=2.02\). Again, the sample standard deviation formula produces a result that is closer to 2.02 than does the population deviation formula.
What if we did this for 20,000 samples of size 10? We’ll save the estimates using the sample SD formula in the object results.samp.sd and the estimates using the population SD formula in results.pop.sd. Again, don’t worry about the code here - just focus on the output:
results.samp.sd<- vector('list',20000)
results.pop.sd<- vector('list',20000)
for(i in 1:20000){
samp <- sample(pop, size = 10, replace = T)
results.samp.sd[[i]] <- sd(samp)
results.pop.sd[[i]] <- pop.sd(samp)
}We can work out the average estimate of the standard deviation across all 20,000 samples:
mean(unlist(results.samp.sd))## [1] 1.967842mean(unlist(results.pop.sd))## [1] 1.866859So, over 20,000 samples both formulas actually overall underestimate the true population standard deviation of \(\sigma=2.02\), however, the sample standard deviation formula is closer with it’s average being 1.97 compared to the population standard deviation’s formula being at 1.87.
We can graph this like this:
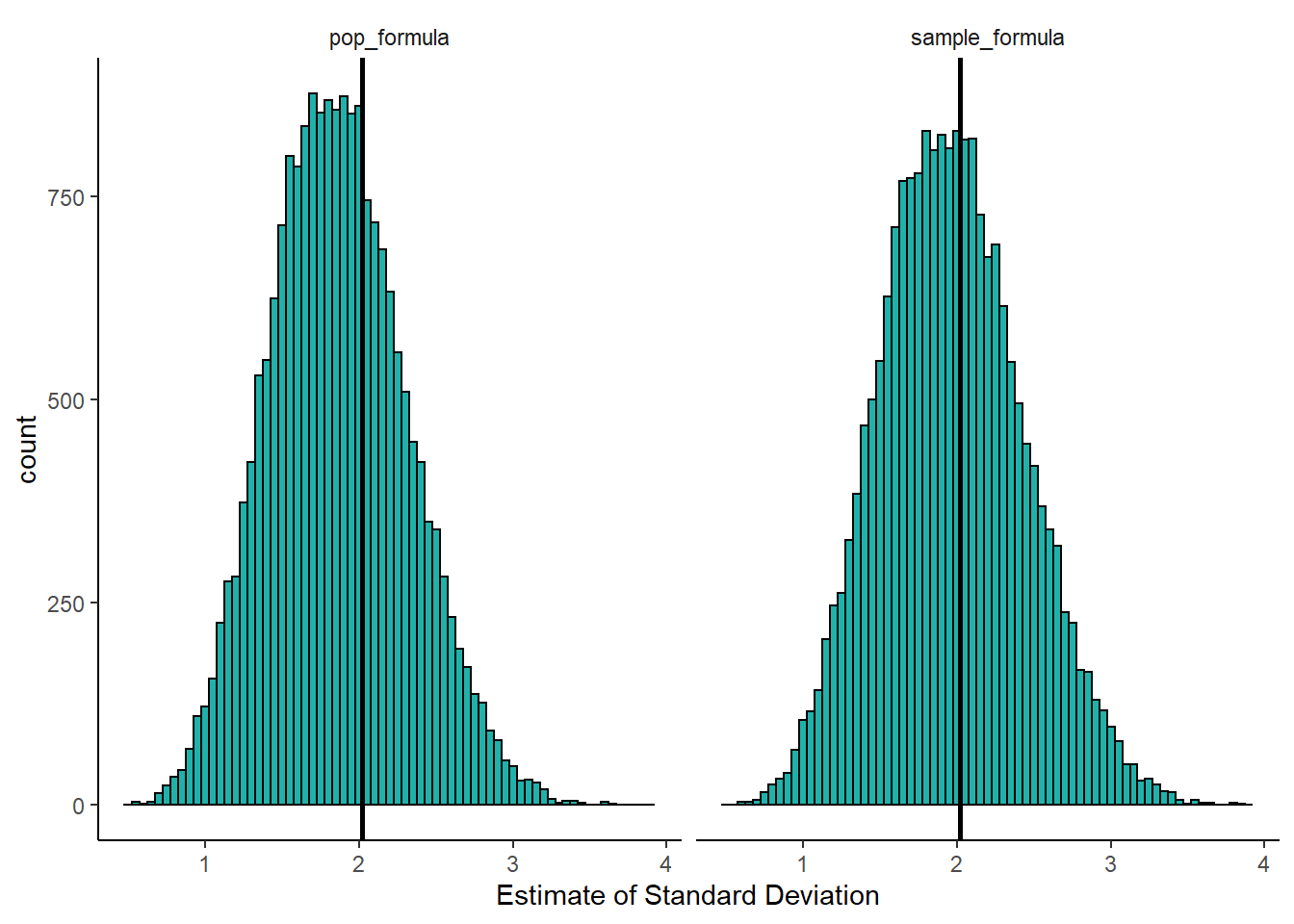
This visualization shows us a few things. First, over all 20,000 samples, some of our estimates of the true standard deviation \(\sigma\) are higher and some are lower regardless of which formula we use. However, when we use the population formula (dividing by \(N\)), we have far more samples with estimates of the standard deviation \(\sigma\) which are too low. The distribution is clearly not symmetrical. If we consider the right histogram, when we use the sample SD formula (dividing by \(n-1\)), we correct this by and large. This histogram is closer to symmetrical, and we are not underestimating the true population standard deviation nearly as much. In this way, we called the sample standard deviation \(s\) an unbiased estimator.
If we were to take larger sample sizes, then our estimates of the population standard deviation \(\sigma\), would get better and better when using the sample standard deviation formula.
6.5 Descriptive Statistics in R
The above sections interweaved some theory with how to get descriptive information using R. In this section we’ll summarize how to get descriptive summaries from real data in R.
The dataset that we’ll use is a year’s worth of temperature data from Austin, TX.
atx <- read_csv("data/austin_weather.csv")
head(atx) # first 6 rows## # A tibble: 6 x 4
## month day year temp
## <dbl> <dbl> <dbl> <dbl>
## 1 1 1 2019 43.3
## 2 1 2 2019 39.4
## 3 1 3 2019 41.2
## 4 1 4 2019 44.1
## 5 1 5 2019 48.6
## 6 1 6 2019 48.8The temp column shows the average temperature for that day of the year in 2019. Here is a histogram showing the distribution. It is often hot in Texas.
ggplot(atx, aes(x= temp)) +
geom_histogram(color="black", fill="lightseagreen", binwidth = 2)+
theme_classic()+
xlab("Average temperature")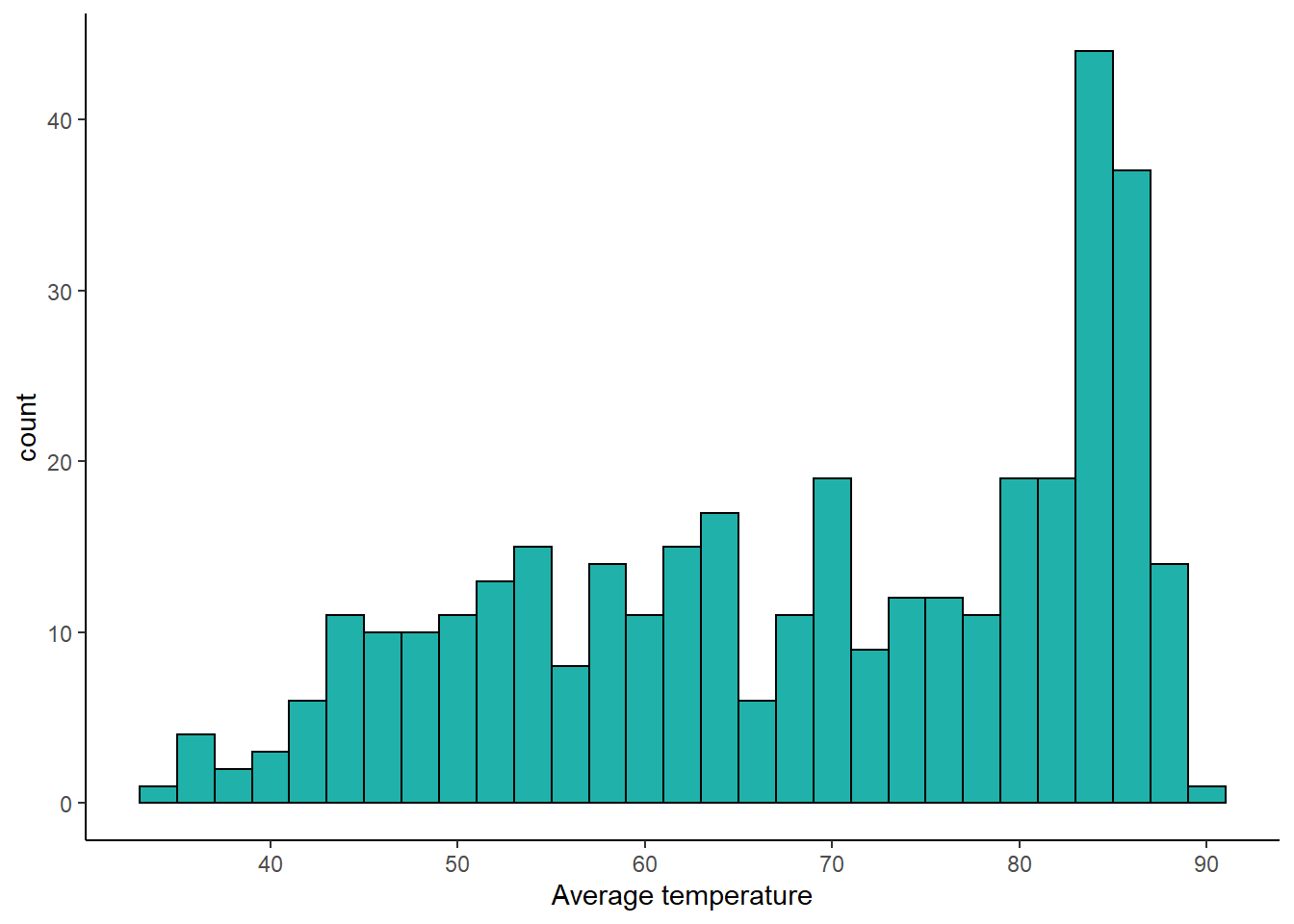
Basic Descriptives
Here is a list of some the basic descriptive commands such as calculating the \(n\), the minimum, maximum and range. We apply each function to the whole column of data atx$temp, i.e. all the numbers of the distribution:
length(atx$temp) # length this tells you the 'n'## [1] 365range(atx$temp) # range ## [1] 34.5 89.2min(atx$temp) # minimum## [1] 34.5max(atx$temp) # maximum## [1] 89.2Mean, Median, and Mode
These mean and median are straightforward in R:
mean(atx$temp) # mean## [1] 68.78767median(atx$temp) # median## [1] 70.8For some descriptives, like mode, there is not a function already built into R. One option is to use table() to get frequencies - but this isn’t useful when you have relatively large datasets. The output is too large. Another option is to use tidyverse methods. Here, we use group_by() to get each temperature, then we use count() to count how many of each temperature we have, and then arrange() to determine which is most frequent:
atx %>%
group_by(temp) %>%
count() %>%
arrange(-n)## # A tibble: 248 x 2
## # Groups: temp [248]
## temp n
## <dbl> <int>
## 1 84.8 5
## 2 51.6 4
## 3 75.5 4
## 4 83.7 4
## 5 84.2 4
## 6 84.3 4
## 7 84.9 4
## 8 86.1 4
## 9 42.3 3
## 10 52 3
## # ... with 238 more rowsThis shows us that the modal value is 84.8F. In reality however, the mode is never something that you will calculate outside of an introductory stats class.
Variation
The default standard variation measure in R is the sample standard deviation sd(), and is the one you should pretty much always use:
sd(atx$temp) # sample standard deviation## [1] 14.90662Variance can also be calculated using var() - remember this is the standard deviation squared. When you calculate this using the sample standard deviation \(s\) the formula notation for the variance is \(s^2\):
var(atx$temp) # variance ## [1] 222.2072The lower quartile, upper quartile and inter-quartile range can be calculated like this:
quantile(atx$temp, .25) # this is the lower quartile## 25%
## 56.5quantile(atx$temp, .75) # this is the upper quartile## 75%
## 83.3IQR(atx$temp) # this is the inter-quartile range.## [1] 26.8Remember there are several ways of calculating the quartiles (see above).
6.5.1 Dealing with Missing Data
Often in datasets we have missing data. In R, missing data in our dataframes or vectors is represented by NA or sometimes NaN. A slightly annoying feature of many of the descriptive summary functions is that they do not work if there is missing data.
Here’s an illustration. We’ve created a vector of data called q that has some numbers but also a ‘missing’ piece of data:
q <- c(5, 10, 8, 3, NA, 7, 1, 2)
q## [1] 5 10 8 3 NA 7 1 2If we try and calculate some descriptives, R will not like it:
mean(q)## [1] NAsd(q)## [1] NArange(q)## [1] NA NAmedian(q)## [1] NAWhat we have to do in these situations is to override the missing data. We need to tell it that we really do want to get these values and it should remove the missing data before doing that. We do that by adding the argument na.rm=T to the end of each function:
mean(q, na.rm=T)## [1] 5.142857sd(q, na.rm=T)## [1] 3.338092range(q, na.rm=T)## [1] 1 10median(q, na.rm=T)## [1] 5Now R is happy to do what we want.
The only ‘gotcha’ that you need to watch out for is length() which we sometimes use to calculate the \(n\) of a vector. If we do this for q, we’ll get 8, which includes our missing value:
length(q)## [1] 8This is a way of getting around that - it looks odd, so we’ve just put it here for reference. It’s not necessary for you to remember this. It’s essentially asking what is the length of q when you don’t include the NA:
length(q[!is.na(q)])## [1] 76.6 Descriptives for Datasets
Often in studies, we are interested in many different outcome variables at once. We are also interested in how groups differ in various descriptive statistics. The following code will show you how to get descriptive statistics for several columns. In the next section we’ll discuss getting descriptives for different groups from data.
First read in these data that are looking at various sales of different video games.
vg <- read_csv("data/videogames.csv")
head(vg)## # A tibble: 6 x 12
## name platform year genre publisher NA_sales EU_sales JP_sales global_sales
## <chr> <chr> <dbl> <chr> <chr> <dbl> <dbl> <dbl> <dbl>
## 1 Wii Sp~ Wii 2006 Spor~ Nintendo 41.4 29.0 3.77 82.5
## 2 Mario ~ Wii 2008 Raci~ Nintendo 15.7 12.8 3.79 35.6
## 3 Wii Sp~ Wii 2009 Spor~ Nintendo 15.6 11.0 3.28 32.8
## 4 Wii Fit Wii 2007 Spor~ Nintendo 8.92 8.03 3.6 22.7
## 5 Wii Fi~ Wii 2009 Spor~ Nintendo 9.01 8.49 2.53 21.8
## 6 Grand ~ PS3 2013 Acti~ Take-Two~ 7.02 9.14 0.98 21.1
## # ... with 3 more variables: critic <dbl>, user <dbl>, rating <chr>One way to get quick summary information is to use the R function summary() like this:
summary(vg)## name platform year genre
## Length:2502 Length:2502 Min. :1992 Length:2502
## Class :character Class :character 1st Qu.:2005 Class :character
## Mode :character Mode :character Median :2008 Mode :character
## Mean :2008
## 3rd Qu.:2011
## Max. :2016
## publisher NA_sales EU_sales JP_sales
## Length:2502 Min. : 0.0000 Min. : 0.0000 Min. :0.00000
## Class :character 1st Qu.: 0.0700 1st Qu.: 0.0200 1st Qu.:0.00000
## Mode :character Median : 0.1800 Median : 0.1000 Median :0.00000
## Mean : 0.4852 Mean : 0.3012 Mean :0.04023
## 3rd Qu.: 0.4675 3rd Qu.: 0.2800 3rd Qu.:0.01000
## Max. :41.3600 Max. :28.9600 Max. :3.79000
## global_sales critic user rating
## Min. : 0.0100 Min. :13.00 Min. :0.700 Length:2502
## 1st Qu.: 0.1500 1st Qu.:61.00 1st Qu.:6.200 Class :character
## Median : 0.3800 Median :72.00 Median :7.400 Mode :character
## Mean : 0.9463 Mean :69.98 Mean :7.027
## 3rd Qu.: 0.9275 3rd Qu.:81.00 3rd Qu.:8.100
## Max. :82.5400 Max. :98.00 Max. :9.300You’ll notice here that it just gives you some summary information for different columns, even those that have no numerical data in them. It’s also not broken down by groups. However, summary() can be a quick way to get some summary information.
A slightly better function is Describe() in the psych package. Remember to install the psych package before using it. Also, here we are telling it only to provide summaries of the relevant numeric columns (which are the 6th through 11th columns):
library(psych)
describe(vg[c(6:11)])## vars n mean sd median trimmed mad min max range skew
## NA_sales 1 2502 0.49 1.29 0.18 0.27 0.21 0.00 41.36 41.36 15.79
## EU_sales 2 2502 0.30 0.90 0.10 0.15 0.13 0.00 28.96 28.96 16.63
## JP_sales 3 2502 0.04 0.20 0.00 0.01 0.00 0.00 3.79 3.79 12.05
## global_sales 4 2502 0.95 2.56 0.38 0.53 0.42 0.01 82.54 82.53 16.52
## critic 5 2502 69.98 14.34 72.00 71.03 14.83 13.00 98.00 85.00 -0.67
## user 6 2502 7.03 1.44 7.40 7.19 1.33 0.70 9.30 8.60 -1.06
## kurtosis se
## NA_sales 422.23 0.03
## EU_sales 444.50 0.02
## JP_sales 191.56 0.00
## global_sales 441.74 0.05
## critic 0.07 0.29
## user 1.06 0.03This function also includes some descriptives that we don’t necessarily need to worry about right now, but it does contain most of the ones we are concerned with.
6.6.1 Descriptives for Groups
There are a few ways of getting descriptives for different groups. In our videogame dataset vg, we have a column called genre. We can use the function table() to get the \(n\) for all groups.
table(vg$genre)##
## Action Racing Shooter Sports
## 997 349 583 573We have four different groups of genres, and we might want to get descriptives for each. We can use the function describeBy() from the psych package to get a very quick and easy, but a bit annoying, look at group summaries. It also ignores missing data which is helpful. We dictate which group to get summaries by using the group = "genre" argument:
describeBy(vg[c(4,6:11)], group = "genre")##
## Descriptive statistics by group
## genre: Action
## vars n mean sd median trimmed mad min max range skew
## genre* 1 997 1.00 0.00 1.00 1.00 0.00 1.00 1.00 0.00 NaN
## NA_sales 2 997 0.41 0.82 0.17 0.24 0.19 0.00 9.66 9.66 6.19
## EU_sales 3 997 0.27 0.58 0.10 0.15 0.13 0.00 9.14 9.14 7.14
## JP_sales 4 997 0.05 0.14 0.00 0.01 0.00 0.00 1.13 1.13 4.44
## global_sales 5 997 0.83 1.67 0.36 0.50 0.39 0.01 21.12 21.11 6.66
## critic 6 997 68.02 14.21 70.00 68.63 14.83 20.00 98.00 78.00 -0.38
## user 7 997 7.12 1.34 7.40 7.26 1.19 1.70 9.30 7.60 -1.04
## kurtosis se
## genre* NaN 0.00
## NA_sales 52.60 0.03
## EU_sales 77.32 0.02
## JP_sales 22.38 0.00
## global_sales 61.52 0.05
## critic -0.31 0.45
## user 1.05 0.04
## ------------------------------------------------------------
## genre: Racing
## vars n mean sd median trimmed mad min max range skew
## genre* 1 349 1.00 0.00 1.00 1.00 0.00 1.00 1.00 0.00 NaN
## NA_sales 2 349 0.40 1.03 0.13 0.22 0.18 0.00 15.68 15.68 10.36
## EU_sales 3 349 0.31 0.85 0.10 0.17 0.13 0.00 12.80 12.80 10.23
## JP_sales 4 349 0.03 0.24 0.00 0.00 0.00 0.00 3.79 3.79 12.65
## global_sales 5 349 0.86 2.36 0.30 0.48 0.36 0.01 35.57 35.56 10.34
## critic 6 349 69.84 14.01 72.00 71.18 14.83 13.00 95.00 82.00 -0.92
## user 7 349 6.99 1.50 7.30 7.16 1.48 1.00 9.20 8.20 -1.05
## kurtosis se
## genre* NaN 0.00
## NA_sales 140.24 0.06
## EU_sales 135.03 0.05
## JP_sales 180.01 0.01
## global_sales 136.42 0.13
## critic 0.87 0.75
## user 1.06 0.08
## ------------------------------------------------------------
## genre: Shooter
## vars n mean sd median trimmed mad min max range skew
## genre* 1 583 1.00 0.00 1.00 1.00 0.00 1.00 1.00 0.00 NaN
## NA_sales 2 583 0.56 1.22 0.16 0.27 0.21 0.00 9.73 9.73 4.41
## EU_sales 3 583 0.33 0.67 0.10 0.18 0.13 0.00 5.73 5.73 4.46
## JP_sales 4 583 0.02 0.07 0.00 0.01 0.00 0.00 0.88 0.88 6.43
## global_sales 5 583 1.02 2.09 0.35 0.54 0.43 0.01 14.77 14.76 4.20
## critic 6 583 70.49 15.12 73.00 71.71 14.83 27.00 96.00 69.00 -0.68
## user 7 583 6.95 1.54 7.30 7.14 1.33 1.20 9.30 8.10 -1.14
## kurtosis se
## genre* NaN 0.00
## NA_sales 22.41 0.05
## EU_sales 24.55 0.03
## JP_sales 52.31 0.00
## global_sales 19.81 0.09
## critic -0.18 0.63
## user 1.08 0.06
## ------------------------------------------------------------
## genre: Sports
## vars n mean sd median trimmed mad min max range skew
## genre* 1 573 1.00 0.00 1.00 1.00 0.00 1.00 1.00 0.00 NaN
## NA_sales 2 573 0.60 1.99 0.27 0.35 0.28 0.00 41.36 41.36 16.15
## EU_sales 3 573 0.33 1.44 0.08 0.13 0.12 0.00 28.96 28.96 15.26
## JP_sales 4 573 0.05 0.30 0.00 0.00 0.00 0.00 3.77 3.77 9.54
## global_sales 5 573 1.11 4.00 0.50 0.64 0.50 0.01 82.54 82.53 16.17
## critic 6 573 72.95 13.44 76.00 74.42 10.38 19.00 97.00 78.00 -1.10
## user 7 573 6.97 1.46 7.30 7.12 1.33 0.70 9.20 8.50 -0.92
## kurtosis se
## genre* NaN 0.00
## NA_sales 312.92 0.08
## EU_sales 282.22 0.06
## JP_sales 100.35 0.01
## global_sales 307.46 0.17
## critic 1.26 0.56
## user 0.68 0.06The above is a quick and dirty way of getting summary information by group. But it is messy. We suggest an alternative method which is to write code using the tidyverse package. This can give us descriptive statistics in a more organized way.
For instance, if we wanted to get the mean of the column NA_sales by genre we would use group_by() and summarise() in this way:
vg %>%
group_by(genre) %>%
summarise(meanNA = mean(NA_sales))## # A tibble: 4 x 2
## genre meanNA
## <chr> <dbl>
## 1 Action 0.407
## 2 Racing 0.397
## 3 Shooter 0.555
## 4 Sports 0.603The above code can be read as taking the dataset vg, and then grouping it by the column genre, and then summarizing the data to get the mean of the NA_sales column by group/genre. Please not the British spelling of summarise(). The tidyverse was originally written using British spelling, and although R is usually fine with British or US spelling, this is one situation in which it is usually helpful to stick with the British spelling for boring reasons.
If you had missing data, you’d do it like this.
vg %>%
group_by(genre) %>%
summarise(meanNA = mean(NA_sales, na.rm = T)) ## # A tibble: 4 x 2
## genre meanNA
## <chr> <dbl>
## 1 Action 0.407
## 2 Racing 0.397
## 3 Shooter 0.555
## 4 Sports 0.603You can do several summaries at once like this. Here we are getting the means and sample standard deviations of the NA_sales and EU_sales columns by genre:
vg %>%
group_by(genre) %>%
summarise(meanNA = mean(NA_sales),
sd_NA = sd(NA_sales),
meanEU = mean(EU_sales),
sd_EU = sd(EU_sales))## # A tibble: 4 x 5
## genre meanNA sd_NA meanEU sd_EU
## <chr> <dbl> <dbl> <dbl> <dbl>
## 1 Action 0.407 0.819 0.267 0.577
## 2 Racing 0.397 1.03 0.309 0.852
## 3 Shooter 0.555 1.22 0.331 0.667
## 4 Sports 0.603 1.99 0.326 1.44To save time, you can tell it to just get the summary of all numeric columns by using summarise_if().
vg$year <- as.factor(vg$year) # just need to make year non-numeric first so doesn't get included in the numeric columns
vg %>%
group_by(genre) %>%
summarise_if(is.numeric, mean, na.rm = T) %>%
as.data.frame()## genre NA_sales EU_sales JP_sales global_sales critic user
## 1 Action 0.4071013 0.2668004 0.04857573 0.8349649 68.01605 7.117954
## 2 Racing 0.3967908 0.3085100 0.03246418 0.8630946 69.84241 6.991691
## 3 Shooter 0.5554717 0.3310292 0.02288165 1.0245969 70.48714 6.948885
## 4 Sports 0.6034031 0.3260733 0.04808028 1.1108028 72.94764 6.970157 vg %>%
group_by(genre) %>%
summarise_if(is.numeric, sd, na.rm = TRUE) %>%
as.data.frame()## genre NA_sales EU_sales JP_sales global_sales critic user
## 1 Action 0.8189867 0.5772930 0.14425469 1.670552 14.20560 1.339989
## 2 Racing 1.0315188 0.8522769 0.24017403 2.363348 14.00640 1.497225
## 3 Shooter 1.2165479 0.6674269 0.07343275 2.087551 15.11614 1.540249
## 4 Sports 1.9868151 1.4352370 0.30421425 3.996394 13.44039 1.4637346.6.2 Counts by Group
Another common use of group_by() is to get counts of how many we have of each categorical variable. For instance, let’s look more at the videogames dataset vg.
We have previously seen that we can use table() to count simple frequencies. For instance, the following:
table(vg$genre)##
## Action Racing Shooter Sports
## 997 349 583 573shows us how many observations of each genre we have. We have 997 Action games, 349 Racing games, 583 shooter games and 573 sports games.
We can look at how these breakdown by platform by adding one more argument into our table() function which relates to our second column of interest:
table(vg$genre, vg$platform)##
## PC PS2 PS3 Wii X360
## Action 144 247 237 127 242
## Racing 48 135 63 30 73
## Shooter 144 128 123 30 158
## Sports 32 203 116 79 143We can see here that we have 32 Sports games on the PC, 135 racing games on the PS2 and so on.
This is a nice and straightforward way of doing this. It’s also possible to do it using the tidyverse() which can come in handy sometimes in some circumstances. To do it this way, we make use of group_by() and count(). We tell it the two columns we wish to group our data by (in this case it is the genre and the platform columns), and then tell it to count how many observations we have:
vg %>%
group_by(genre, platform) %>%
count()## # A tibble: 20 x 3
## # Groups: genre, platform [20]
## genre platform n
## <chr> <chr> <int>
## 1 Action PC 144
## 2 Action PS2 247
## 3 Action PS3 237
## 4 Action Wii 127
## 5 Action X360 242
## 6 Racing PC 48
## 7 Racing PS2 135
## 8 Racing PS3 63
## 9 Racing Wii 30
## 10 Racing X360 73
## 11 Shooter PC 144
## 12 Shooter PS2 128
## 13 Shooter PS3 123
## 14 Shooter Wii 30
## 15 Shooter X360 158
## 16 Sports PC 32
## 17 Sports PS2 203
## 18 Sports PS3 116
## 19 Sports Wii 79
## 20 Sports X360 143These data are presented in a slightly different way. The count of each combination is shown in the new n column. The nice thing about this tidy approach is that we can further manipulate the data. This is better illustrated with an even busier dataset, the catcolor.csv dataset:
cats <- read_csv("data/catcolor.csv")
head(cats)## # A tibble: 6 x 7
## animal_id monthyear name color1 color2 sex breed
## <chr> <dttm> <chr> <chr> <chr> <chr> <chr>
## 1 A685067 2014-08-14 18:45:00 Lucy blue white Female domestic short~
## 2 A678580 2014-06-29 17:45:00 Frida white black Female domestic short~
## 3 A675405 2014-03-28 14:55:00 Stella Luna black white Female domestic mediu~
## 4 A684460 2014-08-13 15:04:00 Elsa brown <NA> Female domestic short~
## 5 A686497 2014-08-31 15:45:00 Chester black <NA> Male domestic short~
## 6 A687965 2014-10-31 18:29:00 Oliver orange <NA> Male domestic short~Say we want to know how many male and female cats of each breed we have. With tidyverse, we would do it like this:
cats %>%
group_by(breed,sex) %>%
count()## # A tibble: 87 x 3
## # Groups: breed, sex [87]
## breed sex n
## <chr> <chr> <int>
## 1 abyssinian Female 2
## 2 abyssinian Male 1
## 3 american curl shorthair Female 4
## 4 american curl shorthair Male 1
## 5 american shorthair Female 28
## 6 american shorthair Male 44
## 7 angora Female 4
## 8 angora Male 2
## 9 angora/persian Male 1
## 10 balinese Female 3
## # ... with 77 more rowsThis gives us a lot of information. In fact, we have 87 rows of data. However, we could next sort by the newly created n column, to see which sex/breed combination we have the highest amount of. We can use arrange() to do this:
cats %>%
group_by(breed,sex) %>%
count() %>%
arrange(-n)## # A tibble: 87 x 3
## # Groups: breed, sex [87]
## breed sex n
## <chr> <chr> <int>
## 1 domestic shorthair Male 6303
## 2 domestic shorthair Female 4757
## 3 domestic mediumhair Male 702
## 4 domestic mediumhair Female 512
## 5 domestic longhair Male 381
## 6 domestic longhair Female 328
## 7 siamese Male 214
## 8 siamese Female 135
## 9 maine coon Male 54
## 10 snowshoe Male 45
## # ... with 77 more rowsAnother thing we can do is to count how many there are of a given category or categories that satisfy certain conditions. For example, let’s say we wanted to know the most popular name of each breed for orange cats. We could first filter the data by color1 to only keep orange cats, then group by name and breed and then use count() and arrange():
cats %>%
filter(color1 == "orange") %>%
group_by(name,breed) %>%
count() %>%
arrange(-n)## # A tibble: 1,304 x 3
## # Groups: name, breed [1,304]
## name breed n
## <chr> <chr> <int>
## 1 Oliver domestic shorthair 16
## 2 Oscar domestic shorthair 12
## 3 Ginger domestic shorthair 11
## 4 Sam domestic shorthair 11
## 5 Garfield domestic shorthair 10
## 6 Simba domestic shorthair 10
## 7 Tiger domestic shorthair 10
## 8 Toby domestic shorthair 10
## 9 Charlie domestic shorthair 9
## 10 Milo domestic shorthair 9
## # ... with 1,294 more rowsIt turns out that the most popular names overall for orange cats are for domestic shorthairs who are called Oliver, then Oscar, Ginger, Sam, Garfield and so on.
To do exactly what we said above, we can do something a bit different. After we’ve done all the above, we can then tell the chain that we only want to group by breed this time, and we want to keep the highest value with top_n(1). This returns the following:
cats %>%
filter(color1 == "orange") %>%
group_by(name,breed) %>%
count() %>%
arrange(-n) %>%
group_by(breed) %>%
top_n(1)## # A tibble: 23 x 3
## # Groups: breed [11]
## name breed n
## <chr> <chr> <int>
## 1 Oliver domestic shorthair 16
## 2 Boris domestic mediumhair 5
## 3 Pumpkin domestic mediumhair 5
## 4 Charlie domestic longhair 3
## 5 Gilbert domestic longhair 3
## 6 Pumpkin domestic longhair 3
## 7 Amos american shorthair 2
## 8 Roxy cymric 2
## 9 Alise manx 1
## 10 Ami british shorthair 1
## # ... with 13 more rowsCharlie, Gilbert and Pumpkin are all the most common names for orange domestic longhairs!